
Ultimamente estou me dedicando a aprender algoritmos de machine learning para clusterização.
Para que servem os algoritimos de clusterização?
- Compras online: muitas lojas virtuais usam esses algoritimos para entender nossos gostos e recomendar produtos mais parecidos com no nosso perfil. Quem nunca viu aquela parte do site “Você também pode gostar de…”
- Música: aplicativos agurpam nossas músicas favoritas em playlists automáticas e personalizadas
- Medicina: médicos usam para agrupar pacientes com sintomas semelhantes e encontrar o mellhor tratamento
Quais são os principais algoritimos de clusterização?
K-Means
O K-Means é um dos algoritimos de clusterização mais usados. Ele pode encontrar padrões nos dados sem que eles tenham algum tipo de rótulo. Só o que você precisa saber é o K, ou seja, o número de grupos que você quer formar.
Como o K-Mens funciona?
- Inicialização: você define o número de K (o número de grupos) e ele vai escolher aleatóriamente pontos nos dados que serão os “centróides” iniciais. Esses centróides serão pontos usados como referência para os grupos.
- Atribuição: Cada ponto de dado é atribuído ao cluster em que o centróide está mais próximo. Ele “mede” a distância do dado analisado em relação aos centróides definidos anteriormente, e pega o mais próximo.
- Atualização: Os centróides de cada cluester são reclaculados como a média dos pontos de dados atribuídos a essse cluster.
- Repetição: As etapas 2 e 3 são repetidas até que os centróides não se movam mais significativamente ou que um número máximo de execuções foi atingido.
Mas, não se preocupe, o algoritimo faz isso automaticamente para você.
Vantagens e desvantagens do K-Means
Vantagens:
- Simples e fácil de implementar, o K-Means é bem fácil de entender e explicar como ele chegou nos resultados
- Eficiente: ele geralmente converge rapidamente para uma solução
- Versátil: pode ser aplicado em uma grande variedade de problemas de clusterização
Desvantagens:
- Sensível a inicialização: A escolha dos centróides iniciais tem impacto grande no resultado final.
- Número de clusters (k): você precisa saber antecipadamente quantos clusters vai criar
- Sensível a outliers: outliers (dados muito fora da média) podem distorcer os clusters.
- Clusters esféricos: O K-Means tende a encontrar clusters esféricos o que pode não funcionar bem em clusters com formatos complexos.
Exemplo de código do K-Means
O exemplo abaixo cria um dataframe com dados de altura e peso de 10 pessoas. O K-Means vai classificá-las em 2 grupos (k=2) e exibir o resultado
from sklearn.cluster import KMeans
import pandas as pd
# Cria um DataFrame com dados de altura e peso
data = {'altura': [1.65, 1.70, 1.75, 1.80, 1.85, 1.60, 1.68, 1.72, 1.83, 1.58],
'peso': [60, 65, 70, 75, 80, 55, 63, 68, 78, 50]}
df = pd.DataFrame(data)
# Cria um objeto KMeans com k=2
kmeans = KMeans(n_clusters=2)
# Treina o modelo
kmeans.fit(df)
# Obtém os clusters atribuídos a cada ponto de dado
clusters = kmeans.labels_
# Adiciona os clusters como uma nova coluna ao DataFrame
df['cluster'] = clusters
# Imprime o DataFrame com as atribuições de cluster
print(df)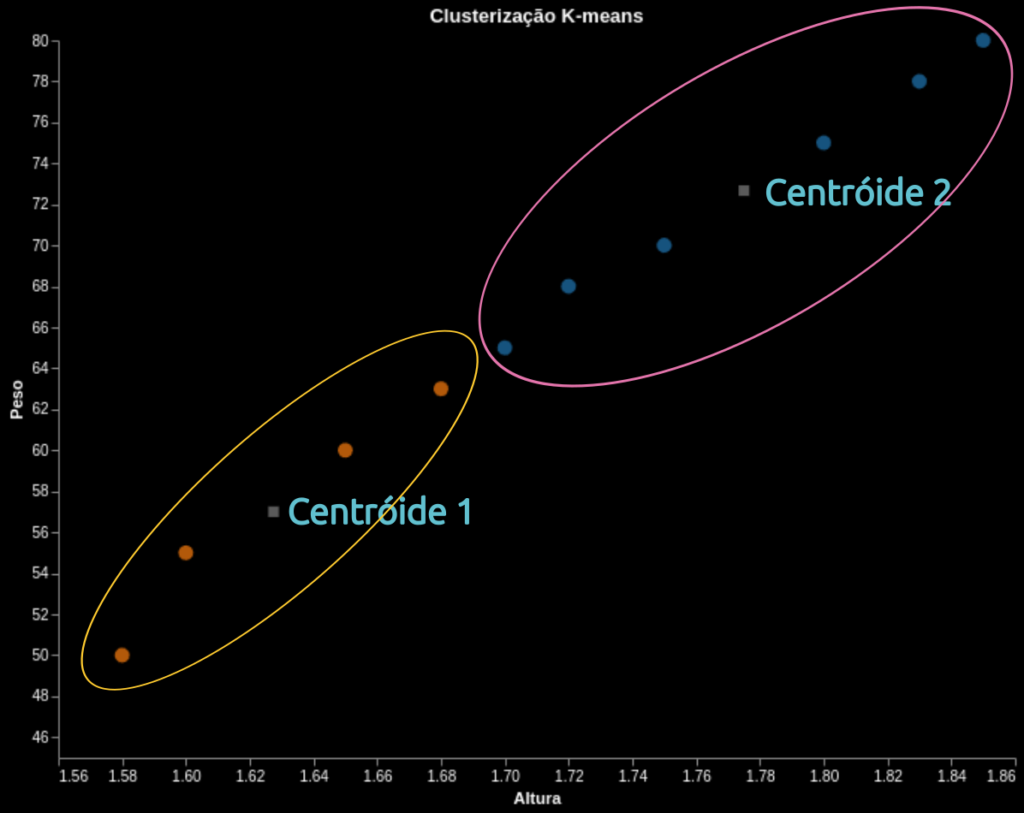
DBSCAN
O DBSCAN (Desity-Based Spatial Clustering of Aplications with Noise) é um algoritimo que clusterização que agrupa pontos com base na densidade em que se encontram, e não em um centróide.
Como o DBSCAN funciona?
O DBSCAN utiliza 2 parâmetros principais:
- Eps: define o raio de vizinhança de um ponto
- MinPts: define o número mínimo de pontos dentro do raio Eps para que um ponto seja considerado um “ponto central” (core point)
Com base nos parâmetros, o DBSCAN classfica os pontos em três tipos:
- Ponto central: um ponto que possui pelo menos
MinPtsvizinhos dentro do raioEps - Ponto de borda: um ponto que possui menos que
MinPtsvizinhos dentro do raioEps, mas está dentro do raioEpsde um ponto central. - Ruído: Um ponto que não é central nem ponto de borda.
Passo a passo do DBSCAN:
- Seleciona um ponto arbitrário que ainda não foi visitado.
- Se o ponto for um ponto central, um novo cluster é criado e todos os seus vizinhos (incluindo pontos de borda) são adicionados ao cluster. Esse processo é repedito recursivamente para cada vizinho.
- Se o ponto for um ponto de borda, ele é adicionado ao cluster do ponto central ao qual está conectado.
- Se o ponto for um ruído, ele é ignorado.
- O processo é repetido até que todos os pontos tenham sido visitados.
Não se preocupe, ele vai fazer isso automaticamente para você.
Vantagens e desvantagens do DBSCAN
Vantagens:
- Descobre clusters de formatos arbitrários: não se limita a custers esféricos como o K-Means
- Robusto a outliers: identifica e ignora pontos de ruído
- Não requer especificação do número de clusters: ele é determinado automaticamente pelo algoritimo
Desvantagens:
- Sensível aos parâmetros: A escolha de
EpseMinPtspode influenciar significativamente o resultado. - Dificuldade com densidades variáveis: Pode ter dificuldades em identificar clusters com densidades muito diferentes.
- Pode ser computacionalmente mais caro que o K-means: Especialmente para conjuntos de dados muito grandes.
from sklearn.cluster import DBSCAN
import pandas as pd
# Cria um DataFrame com dados de altura e peso
data = {'altura': [1.65, 1.70, 1.75, 1.80, 1.85, 1.60, 1.68, 1.72, 1.83, 1.58],
'peso': [60, 65, 70, 75, 80, 55, 63, 68, 78, 50]}
df = pd.DataFrame(data)
# Cria um objeto DBSCAN com eps=5 e min_samples=2
# eps: raio de vizinhança
# min_samples: número mínimo de pontos para formar um cluster
dbscan = DBSCAN(eps=5, min_samples=2)
# treina o modelo
dbscan.fit(df)
# Obtém os clusters atribuídos a cada ponto de dado
clusters = dbscan.labels_
# Adiciona os clusters como uma nova coluna ao DataFrame
df['cluster'] = clusters
# Imprime o DataFrame com as atribuições de cluster
print(df)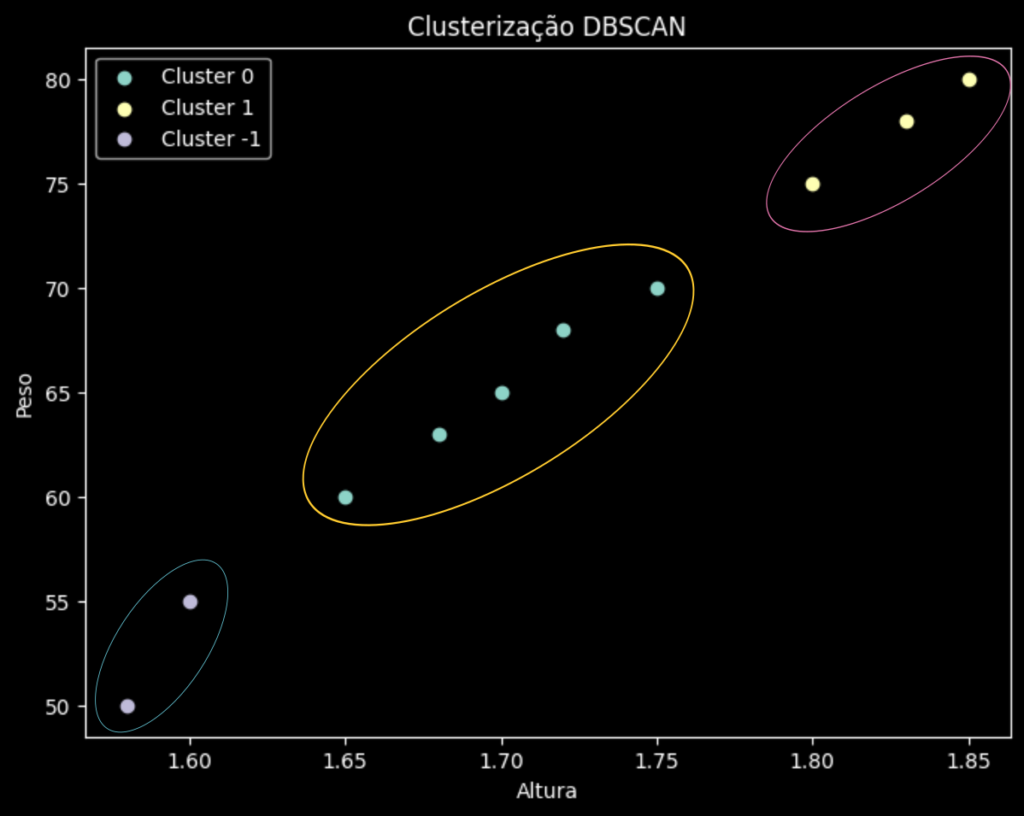
Conclusão
O DBSCAN e o K-Menas são bons algoritimos de clusterização. Enquanto o K-Means criou 2 grupos mais genérico (porque pedimos 2 grupos nos parâmetros), o DBSCAN detectou 3 grupos, sendo o que tem 2 pontos na parte inferior do gráfico foram classificados como ruídos.